Introduction
Knowledge of vocabulary bears the load of comprehension and production of a language and has a fundamental role in learners’ success in L2 communication. The review of the related literature reveals that vocabulary learning as a multi-dimensional issue is viewed and investigated from several aspects (Godfroid, 2020; Nation, 2020; Webb, 2020). Factors such as depth and breadth (Wesche & Paribakht, 1996; Yanagisawa & Webb, 2020), the frequency of occurrence (Laufer & Rozovski-Roitblat, 2011; Webb, 2007a) learning process (Elgort et al., 2018; Pellicer-Sanchez, 2016), comprehension and production (Hsueh-Chao & Nation, 2000; Dang et al., 2017) are only a few dimensions to name. A fundamental issue in vocabulary learning is learners' exposure to the most appropriate type of input. The debate over the kind of input has given way to incidental versus intentional vocabulary learning dichotomy. Incidental learning is interwoven with the type of input fostered by meaning-focused acquisition (Laufer & Rozovski-Roitblat, 2011). However, intentional learning is provided by "exercises and activities designed to explicitly focus students on learning words" (Webb, 2020, p. 5). Although many researchers emphasize the role of meaning-focused input in vocabulary learning, they agree that drawing learners' attention to words facilitates learning (Nation, 2013). Incidental and intentional vocabulary learning has been the source of several studies (e.g., Laufer, 2005; Laufer & Rozovski-Roitblat, 2011; Mizumoto & Takeuchi, 2009) and has caused much debate in the domain due to controversial findings regarding the efficacy of each type of learning. For example, Nation (2001) maintains that specific aspects of word forms, collocations, and parts of speech are best learned via intentional learning procedures. Schmitt (2008) also asserts that an explicit focus on vocabulary is necessary for the learning process. In contrast, several researchers emphasize the role of meaning-focused incidental learning (e.g., Laufer & Rozovski-Roitblat, 2011; Webb, 2008).
Another issue worthy of focus is the role of language skills in vocabulary learning. From the four language skills, reading is the most researched area as it is the source of comprehensible input (Krashen, 1989; Webb, 2008) and is easy to study (Webb, 2020). Studies on writing, though less frequent than reading, have mostly focused on the type of words used by language learners. However, as Webb (2020) argues, listening and speaking have attracted little attention partially because exploring vocabulary acquisition via speaking and listening in the classroom is a challenging task.
Moreover, reading and listening as the two receptive skills are modalities for enhancing incidental vocabulary learning (Gass, 1999). These skills are appropriate sources for an extensive amount of input and can draw learners' attention to vocabulary (Nation, 2020) and facilitate guessing from the context. Multiple researchers have considered reading and listening (e.g., Chen & Truscott, 2010; Pellicer-Sanchez, 2016; van Zeeland & Schmitt, 2013; Vidal, 2011; Webb, 2007b) as the context for examining the role of frequency of occurrence in incidental vocabulary learning.
Another type of input that has recently attracted the focus of researchers is audiovisual input. It has received attention as an alternative way for teaching vocabulary (e.g., Montero Perez et al., 2014; Rodgers, 2013; Winke et al., 2013). The significance of audiovisual input as an authentic source is intensified in EFL situations where learners do not have the opportunity to encounter language in real-life contexts. One reason for the usefulness of audiovisual input is that they provide a framework to promote comprehension by facilitating guessing the meaning of the unknown vocabulary (Nation, 2013).
The present study, in its quest for finding appropriate classroom practices, examined the role of different input-based and output-based activities in enhancing vocabulary acquisition. Nation's (2007) four-strand approach encouraged researchers to design and use a combination of techniques and strategies and examine their efficacy for teaching vocabulary. Nation suggests that the core of successful learning occurs in the process of "meaning-focused input, meaning-focused output, language-focused learning, and fluency development" (p. 2). The researchers postulated that vocabulary acquisition could not be limited to one type of practice due to its complex nature. Educators should consider a range of activities obtained from different theoretical achievements in the domain of language acquisition. As Nation (2007) argues, the purpose of all teaching is "innovation within a framework that fits research findings" (p. 2). Thus, a comparison of a combination of modalities and activities for teaching vocabulary seemed worth researching. This assumption is substantiated by referring to the multimodality theory proposed by Kress (2010). As he argues, the creation of meaning rests upon three features, namely semiotic, conceptual, and affective. During the process of meaning making, individuals not only decode meaning but also give new interpretations to the information they receive based on the three features. The process facilitates the creation of meaning and enhances learning.
The researchers of the present study used TED-ED videos as the context for exposing learners to new words and combined them with another receptive or productive skill followed by both form-focused and meaning-focused writing tasks necessary for promoting vocabulary learning (Pellicer-Sánchez, 2020). The role of the form-focused and meaning-focused tasks used during the intervention was to increase the frequency of exposure to new words. The study also controlled the use of audiovisual materials to examine their efficacy as the primary source of input.
Literature Review
Vocabulary knowledge is at the center of gaining mastery in a second language (Pinker, 1991). Without a sufficient level of vocabulary knowledge, communicating in the language is distorted, if not impossible. The primary purpose of an English teacher is to help students expand their vocabulary knowledge (Nation, 2020). In teaching vocabulary, several aspects such as "form," "meaning," and "use" should be considered. Different views have been put forth for vocabulary learning. One such view is incidental and intentional learning procedures. As Hulstijn (2001) defines it, incidental vocabulary learning occurs when learners are involved in listening, reading, speaking, or writing activities during which they pick up words. However, intentional learning happens with some focus on the vocabulary as when a learner memorizes words from a list.
Despite the typical dichotomy of intentional /incidental instructions, what seems to be vital in vocabulary acquisition is providing opportunities for learners to be engaged in tasks and activities which lead to recognition and production of words in different contexts. The essence of what is encountered in vocabulary learning is explained by Nation (2007) as the combination of activities that can lead to successful vocabulary learning.
Many of the traditional ways of teaching or learning vocabulary seem not to be useful since learners forget words after a while due to the lack of enough exposure. Research findings indicate that learners need to encounter words between 5 to 16 times to learn them (Pellicer-Sánchez & Schmitt, 2010; Webb, 2007b). Current methods of teaching, on the other hand, suggest the benefits of incidental vocabulary learning by fostering meaning-focused instructions (Zimmerman, 2014). However, the role of intentional vocabulary learning is not neglected. The controversy regarding the success of the dichotomy in learning different aspects of vocabulary leads Nation (2013) to value classroom activities that require intentional attention giving weight to the input in which the learners should receive the new words. Thus, the present study aimed to employ a variety of resources and examine how the interaction of different classroom practices could lead to the learning and retention of new words.
With the development and expansion of technology in all areas of people's lives, its application in classrooms has received much attention (Rashtchi & Aghili, 2014; Rashtchi & Tollabi Mazraehno, 2019). The use of multimedia has been the focus of many studies since the type of input provided is authentic, and its use can be a source of motivation for language learners (Plass & Jones, 2005). Paivio's (1986, 2007) Dual Coding Theory can also justify the use of multimedia in which two diverse systems are responsible for the processing of the input received from verbal and non-verbal modes. Another reason for the usefulness of audiovisual input could be found in Baddeley's (1997) theory of working memory. Working memory has a limited capacity and can store information for a limited time. Via his working memory model, Baddeley (1986, 1992) tries to expand both storage and processing of information by postulating a supervisory attentional system that connects a visuo-spatial sketchpad and a phonological loop. As put forth by Baddeley (1986, 1992), input imposes less of a cognitive load on memory when presented in two modes, and thus its retention is more accessible. The presentation of data in different modes (e.g., audio and visual) and storage of small amounts of data in two paths or loops facilitate its transfer to long-term memory and its retrieval.
The beneficial effects of different types of technology have been the focus of several studies. For example, Sydorenko (2010) examined the impact of different input modalities and concluded that the use of video and audio sources enabled the participants to perform better on aural vocabulary tests. Clark (2013) showed that speaking and technological tools could enhance vocabulary learning. Peters et al. (2016) used T.V. programs with captions and L1subtitles to explore their impact on vocabulary learning. They showed that videos could promote incidental vocabulary acquisition, and captions were more beneficial than L1 subtitles in developing vocabulary. Nguyen and Boers (2018) employed a TED Talk video and showed that the sequence of listening, speaking, and listening could lead to more significant results in immediate and delayed vocabulary post-tests.
The present study used TED-ED videos as sources of audiovisual input. The researchers believed that the films meet the contextual richness necessary for guessing word meanings. The animations used in the movies coordinated with interesting content could foster learner involvement in the input received. The animations can draw learners' attention to the vocabulary and promote learning and remembering the words. Additionally, the videos reduce the cognitive load on working memory to facilitate learning. The researchers designed "multimethod research" (Creswell, 2015, p.3) using multiple forms of statistical analyses to explore the topic under scrutiny. The following research questions helped the researchers pursue the objectives:
RQ1: To what extent does audiovisual input provided by TED-ED videos followed by listening, reading, and speaking skills have different impacts on vocabulary learning and retention of EFL learners?
RQ2: To what extent do the results of meaning-focused written tasks and form-focused written exercises across five periods confirm the effectiveness of the treatment?
RQ3: What are the participants' perceptions and preferences regarding the type of treatments they received for vocabulary learning?
Method
Participants
Fifty-six language learners, (30 females and 26 males) in four classes in a language institute in Tehran participated in the study. The classes were intact in the sense that the participants had registered for the classes based on their preferences, and the researchers did not have any role in forming them. Their age range was between 18 and 22 years. They had started learning English in the institute with Top Notch 2 (Saslow & Ascher, 2006a), and at the time of the experimentation, they were going to study Summit 2 (Saslow & Ascher, 2006b). Their language proficiency level, as the book explains, was upper-intermediate or B2 (according to Common European Framework of Reference). The researchers did not use a proficiency test to homogenize them as they had taken the placement test of the institute and had successfully passed the final exams during three previous semesters studying Top Notch 2, 3, and Summit 1. The four groups, selected based on convenience sampling, were randomly assigned to three treatment conditions; namely, audiovisual followed by speaking (AVS-G, 13 participants), audiovisual followed by reading (AVR-G, 14 participants), audiovisual followed by listening (AVL-G, 15 participants), and a control group exposed to listening to the teacher followed by reading (LR-G, 14 participants). Their classes met two times a week for six weeks in the Fall semester, 2019.
Instruments
The first instrument was a Vocabulary Knowledge Scale (VKS), which the researchers used to ensure that the participants did not know the meaning of the target words before the treatment. Eighty words that the researchers, based on their teaching experience, thought might be unfamiliar for the majority of the learners were selected from five TED-ED videos. According to the results, 60 unknown words were considered as the target words (Appendix 1).
To measure the participants' vocabulary learning, a 40-item post-test in multiple-choice format was prepared. The test was administered twice, after the treatment and again within a two-week interval to measure the students' retention. The achievement test was piloted with a group of learners whose language proficiency was higher than the participants of this study. The agreement coefficient of the test computed via the "Subkoviak approach" (Brown, 2005, p. 203) showed an acceptable agreement coefficient index (r=.79).
For each film, the researchers prepared two worksheets, the first worksheet consisted of seven comprehension questions (Appendix 2), and the second one contained ten fill-in-the-blanks items (Appendix 3). The sheets served two purposes. First, they provided more practice on the target words, and second, they enabled the researchers to measure the participants' learning during the treatment. The tasks contained seven comprehension questions based on each video. They could increase the learners' encounter with the target words and enhance incidental vocabulary learning. The second worksheet was given to the learners in the subsequent session and consisted of ten fill-in-the-blanks exercises with 12 words provided in a box (Appendix 3). This worksheet aimed to draw the learners' attention to the target words and promote intentional learning.
The next instrument was a retrospective questionnaire that contained five questions on a five-point Likert scale to help the researchers explore the participants' perceptions regarding the treatment. The survey also included a list of activities that the participants ranked according to their efficacy in the classroom.
Materials
For the study, the researchers downloaded five TED-ED videos and their transcripts from https://www.ted.com/watch/ted-ed . TED-ED videos cover different topics (mostly scientific) such as The science of skin color (for the list of the TED-ED videos used in this study see Table 1). To select the videos, the researchers prepared a list of 15 TED-ED videos that they thought might be interesting for the participants and asked some language learners of the same age to choose the five most interesting ones. Technical words (e.g., dopamine, amygdala, leachate, adenosine) of infrequent use were not selected as the target words, but the teacher was ready to explain if there were any questions. The animations and pictures in the videos facilitated guessing so that it did not seem necessary to focus on all words.
Procedure
The study took twelve sessions: ten for the treatment and two for the administration of the VKS and the immediate post-test. The participants took the delayed post-test as part of their final exam at the language institute. In the experimental groups, two sessions were allocated to each film. In the first session, which took about 50 minutes, the videos were played twice. The target words were selected based on the VKS administered to the participants at the onset of the study.
Table 1 shows the title of the films and the number of target words covered in each session. In the control group, the video transcripts were read out aloud by the teacher two times.
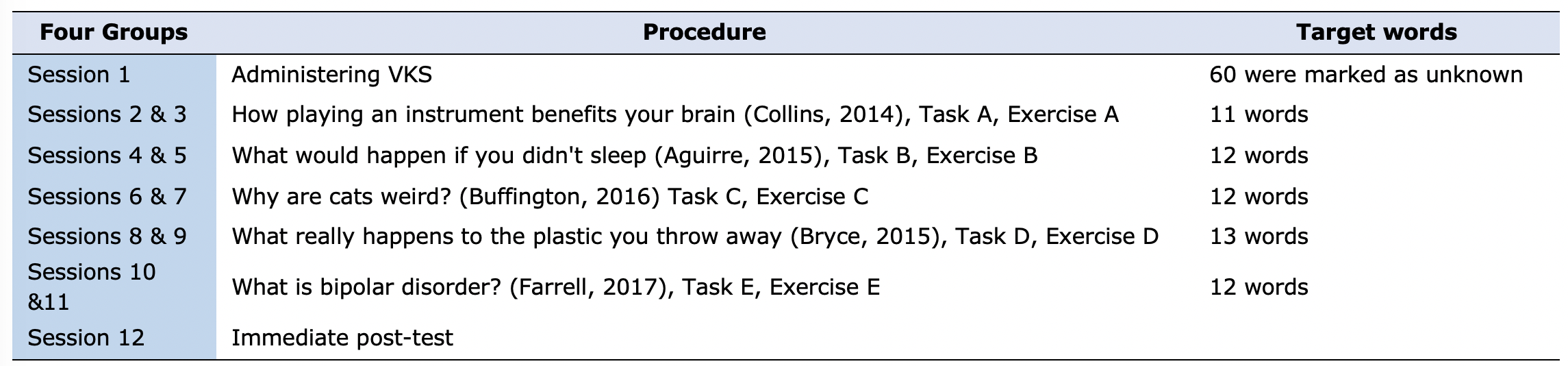
Table 1: Classroom procedure
During the instruction, different vocabulary teaching practices, as presented in Table 2, were manipulated. The activities for each of the study groups were in accordance with the purposes of the study. After watching the TED-ED videos (twice in the three experimental groups), the teacher in AVS-G asked some comprehension questions containing the target words and encouraged the learners to express their viewpoints. The teacher also participated in the discussions and tried to use the new words in her remarks to foster meaning-focused incidental learning. In AVR-G, the participants were given the transcript of the film after watching the films and some time to read the text. While reading, they were free to underline words and look for the words in a dictionary. AVL-G, similar to AVS-G and AVR-G, watched a TED-ED video and then listened to the content of the film without being exposed to the pictures. RL-G (the control group) was not exposed to the TED-ED videos to enable the researchers to control the effect of audiovisual input. The teacher provided the learners with a transcript of the videos and started reading it aloud for two times expressively while the students were reading and listening simultaneously. Then the learners read the passage. They were allowed to underline, highlight, take notes, or use a dictionary.
In the following session, the participants in the experimental groups watched the video once again and completed the second worksheet in 20 minutes (in the control group, the teacher read aloud the transcript). While doing the exercises, the students were not allowed to use a dictionary. The teacher collected both worksheets after completion for further analysis. It is worth mentioning that the time factor was controlled for all groups. Table 2 summarizes the participants' activities in each group.
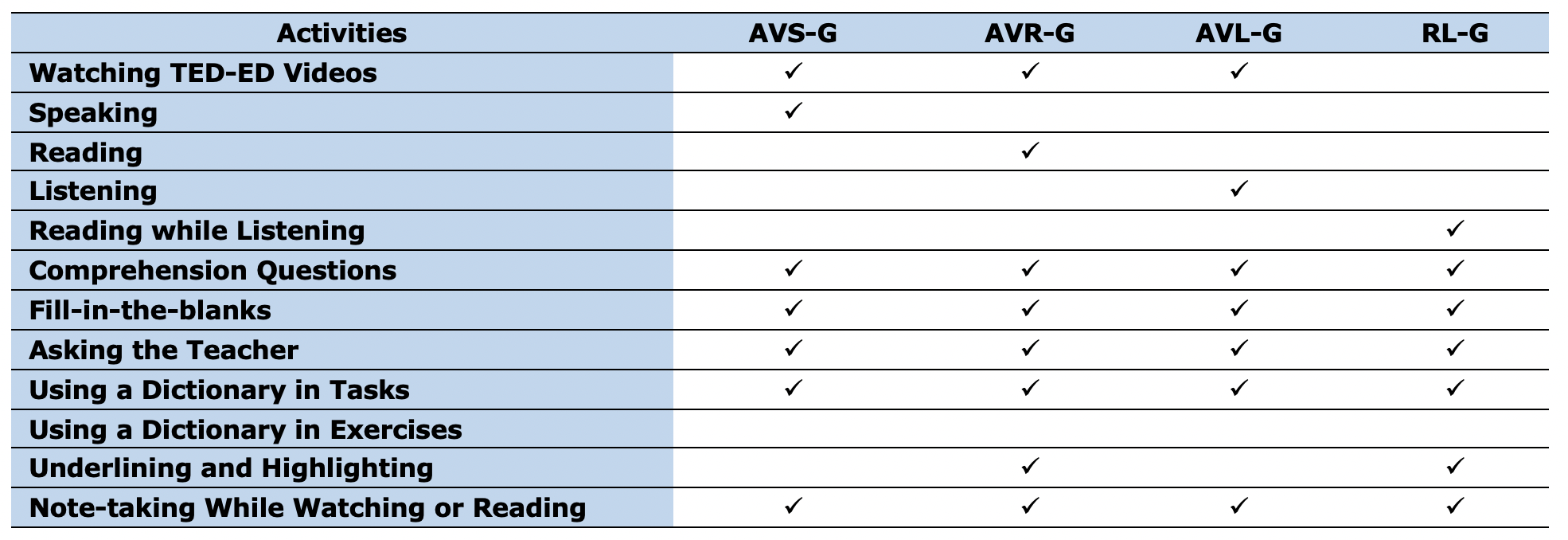
Table 2: Classroom activities in the study groups
Post-tests
All groups took the immediate post-test on the 11th session and again after a two-week interval for the delayed post-test. The items of the immediate post-test were shuffled to control the memory effect.
Results
Multivariate Analysis of Variance (MANOVA) was performed to examine whether there were statistically significant differences between the means of the groups on the two post-tests. Table 3 shows the results of the descriptive statistics obtained from the immediate and delayed vocabulary post-tests. As shown, in the immediate post-test, the AVS-G (M=38.38, SD=1.19) has the highest mean score followed by AVL (M=36.73, SD=.96), AVR-G (M= 28.42, SD=1.34), and LR-G (M=26.71, SD=1.48). The results of the delayed post-test also indicate the highest mean score for AVS-G (M=38.07, SD=1.44) followed by AVL (M=34.66, SD=1.44), AVR-G (M=27.85, SD=1.61) and LR-G (M=25.57, SD=1.08). Overall, all groups show a small decrease in the delayed post-test results.
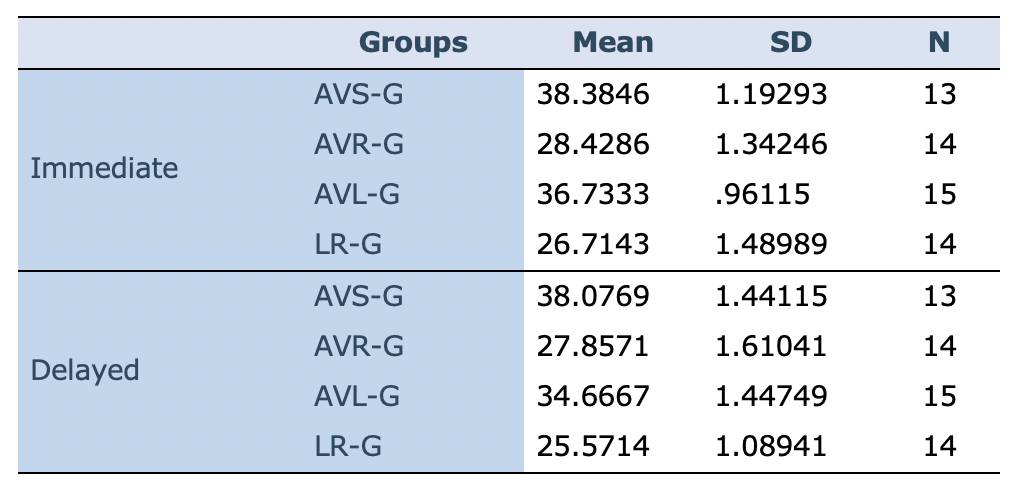
Table 3: Descriptive statistics for immediate and delayed post-tests
For the MANOVA, two preliminary assumptions of normality of the distributions of scores and homogeneity of variance-covariance matrices should be met. Box's test showed that the assumption of normality was not violated (p=.057). Additionally, the Levene's test indicated that the assumption of the homogeneity of variances was met for both post-tests, (p=1.38 for the immediate & p=.599 for the delayed post-tests).
As shown in Table 4, there was a statistically significant difference between the groups on the dependent variables, F (2, 51) =73.348, p<.001; Wilks' Lambda=.035; partial eta squared =.812, indicating a large effect size (Cohen, 1988, pp. 284–287). In other words, 81 percent of the variations in the dependent variables were due to the treatment the participants received.
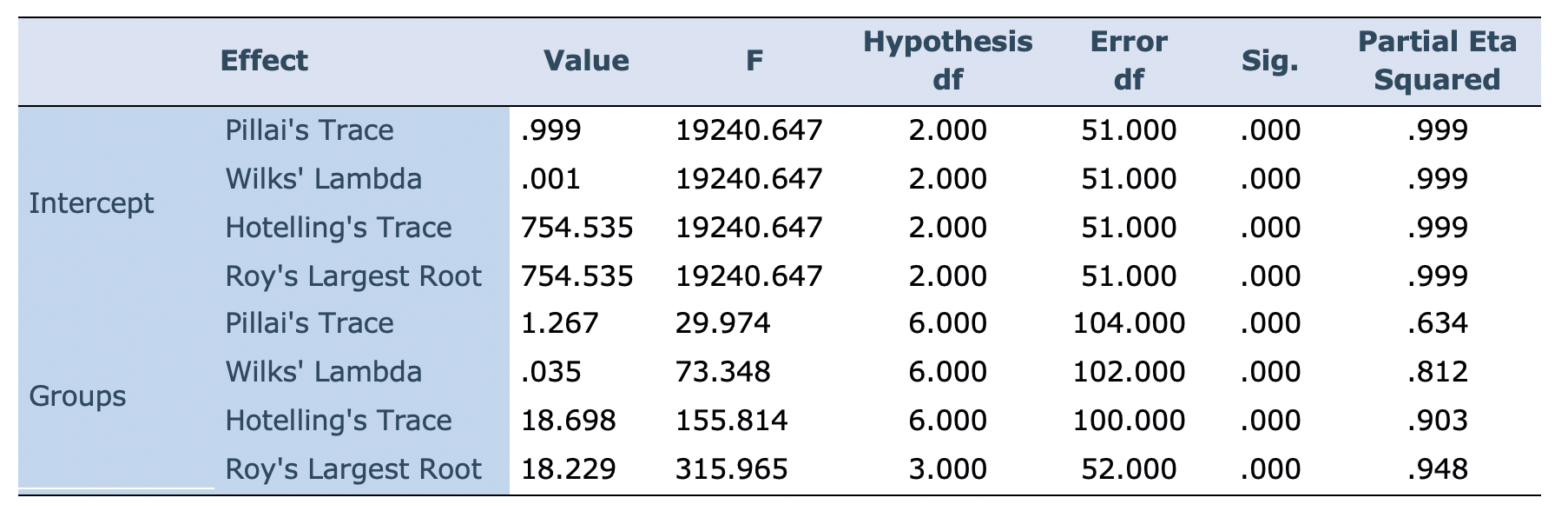
Table 4: Multivariate tests
Tests of between-subjects effects (Table 5) shows separate analyses regarding the dependent variables. Since p values for both immediate and delayed post-tests are smaller than .001, the researchers concluded that there was a statistically significant difference between the groups' performances on the post-tests. Partial eta squared shows a large effect (.945 for the immediate and .931 for the delayed post-tests). In other words, about 90 percent of the variation in the two tests was due to the treatment the participants received.
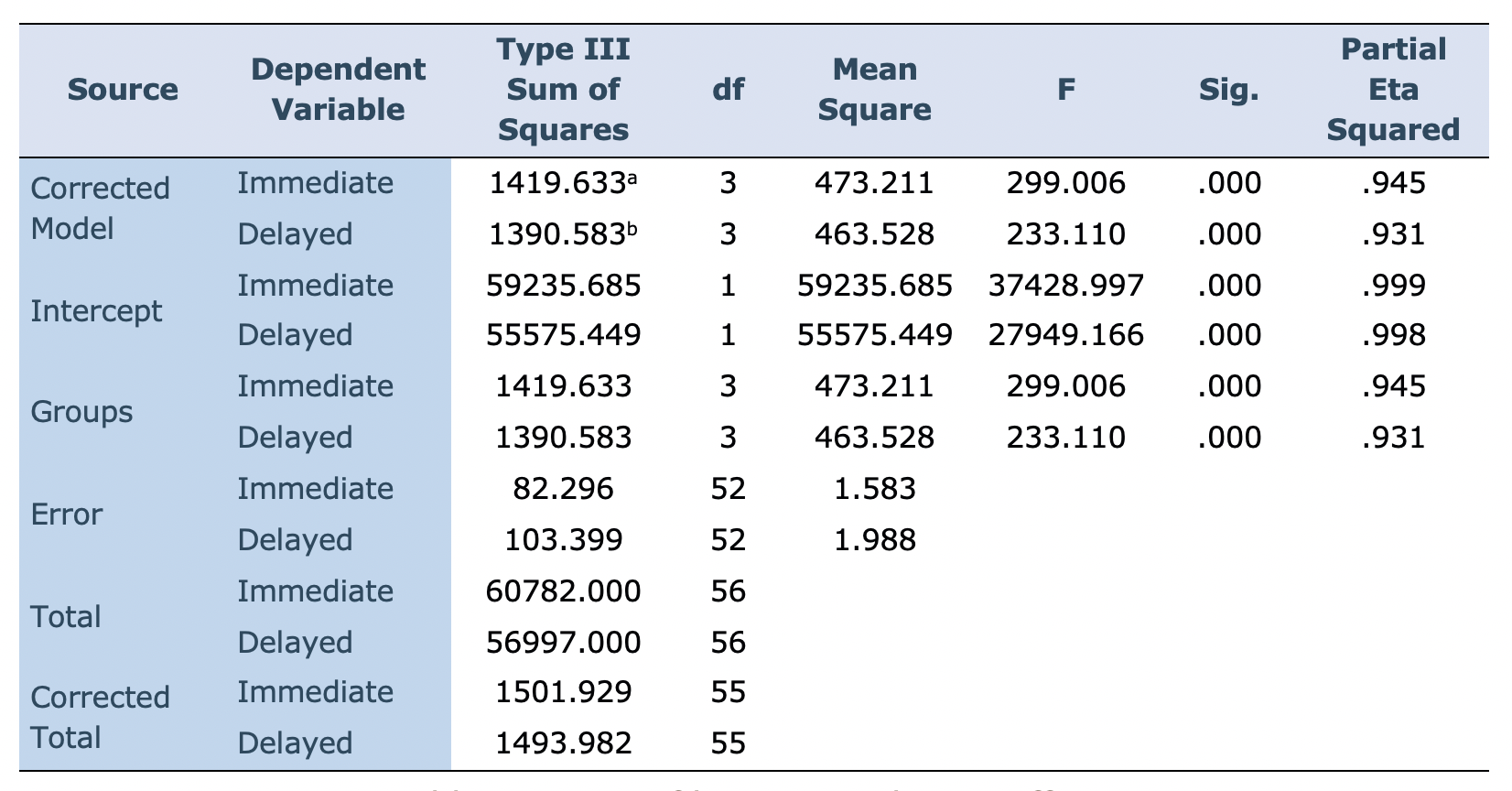
Table 5: Tests of between subjects effects
Post hoc comparisons using the Bonferroni test (Table 6) indicated that the mean score for AVS-G (M=38.38, SD=1.19)) was significantly different from AVL-G (M=36.73, SD=.96), AVR-G (M= 28.42, SD=1.34), and LR-G (M=26.71, SD=1.48) for immediate post-test. Additionally, AVL-G outperformed AVR-G and LR-G, and AVR-G did better than LR-G. Regarding the delayed post-test, post hoc comparisons showed that the mean score for AVS-G (M=38.07, SD=1.44) was significantly different from AVL-G (M=34.66, SD=1.44), AVR-G (M=27.85, SD=1.61), and LR-G (M=25.57, SD=1.08). AVL-G outperformed AVR-G and LR-G, and AVR-G outperformed LR-G (M=27.85, SD=1.61), and LR-G (M=25.57, SD=1.08). AVL-G outperformed AVR-G and LR-G, and AVR-G outperformed LR-G. Thus, the results urged the researchers to conclude that AVS-G was the most successful group in learning and remembering the new vocabulary. Next was AVL-S followed by AVR-G. The least successful group was LR-G, which indicated the usefulness of audiovisual input represented by TED-ED videos.
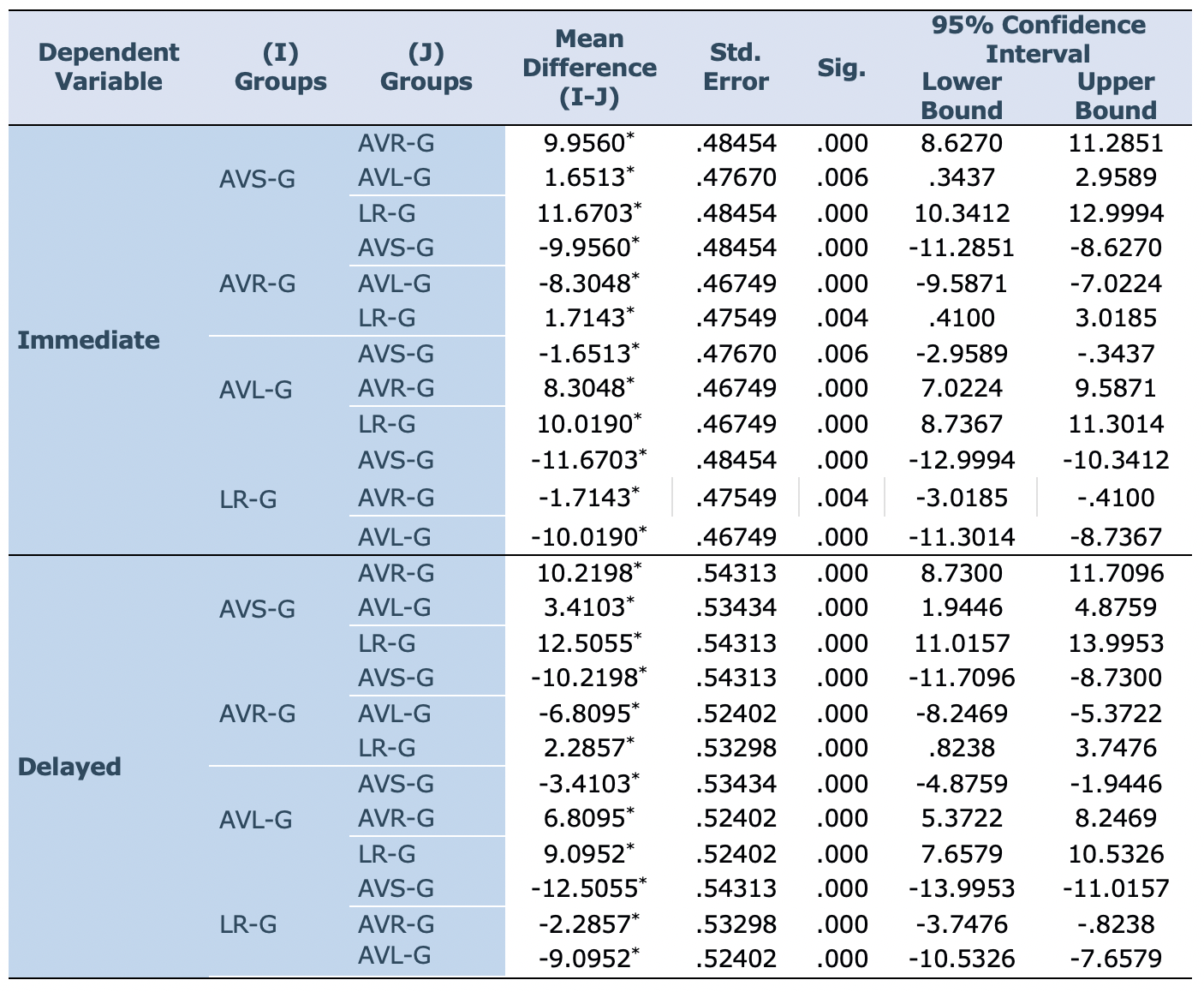
Table 6: Bonferroni Post Hoc Comparisons
Therefore, it could be concluded that watching audiovisual input followed by speaking activities, as conducted in AVS-G, was more effective than other types of activities (listening and reading). As the results indicate, the next successful activity was listening and then reading. In sum, the results indicate that the experimental groups exposed to TED-ED videos did better than the control group.
Analysis of the Worksheets
Comprehension Tasks
The researchers counted the number of times the participants in each group had used the target words accurately in the sentences while answering the questions. They added the frequency of all target words in five tasks and calculated the mean for each group. As Table 7 shows, AVS-G has the highest mean score (M=38.69, SD=5.3), followed by AVL-G (M=32.93, SD=3.99), AVR-G (M=27.07, SD=2.70), and LR-G (M=23.14, SD=3). In other words, audiovisual input followed by speaking enabled AVS-G to use new words more than the other groups when completing the written tasks.
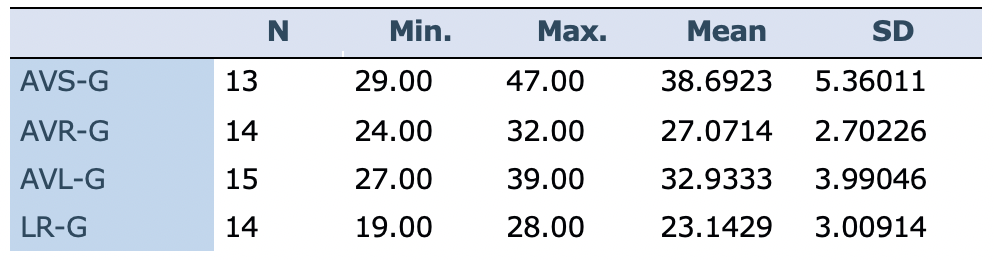
Table 7: Descriptive statistics for the first worksheets (Tasks)
The participants' answers to the second worksheets (fill-in-the-blanks) were scored in each session. A mixed between-within ANOVA was run to examine the impact of different treatment conditions on participants' performance across five periods (for each video). As Table 8 shows, the means of AVS-G were higher than the other groups in all exercises.
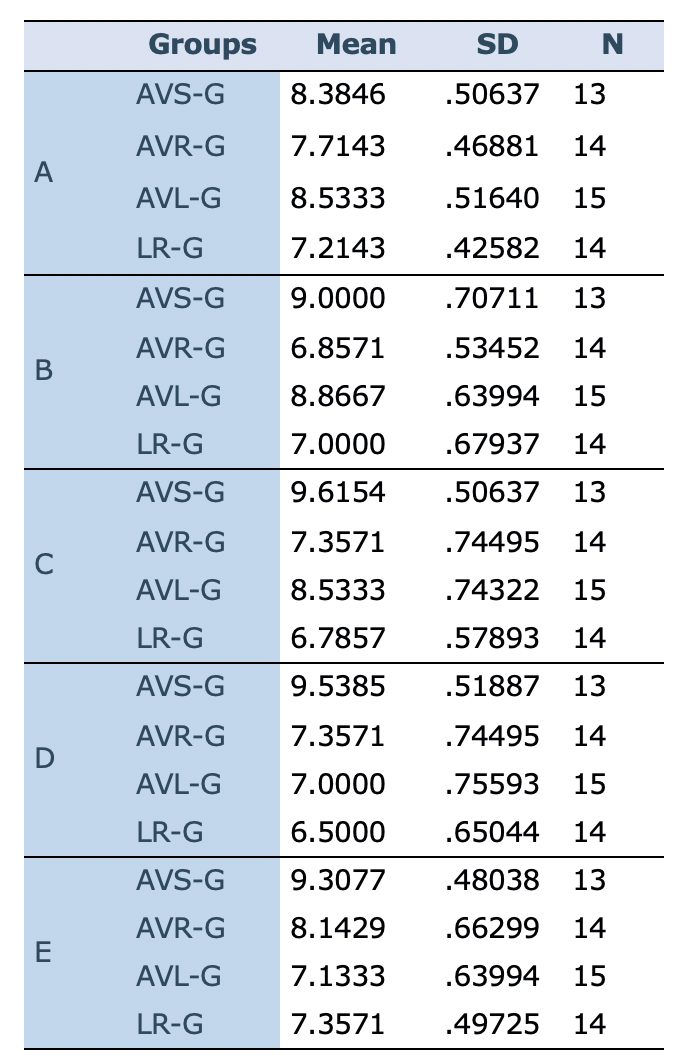
Table 8: Descriptive statistics for the second worksheets (Exercises)
The assumption of the equality of covariance matrices (Box's M) was not violated, (p =.038 was larger than .001).
As shown in Table 9, the assumption of homogeneity of variances is observed, and all p-values are larger than .05.
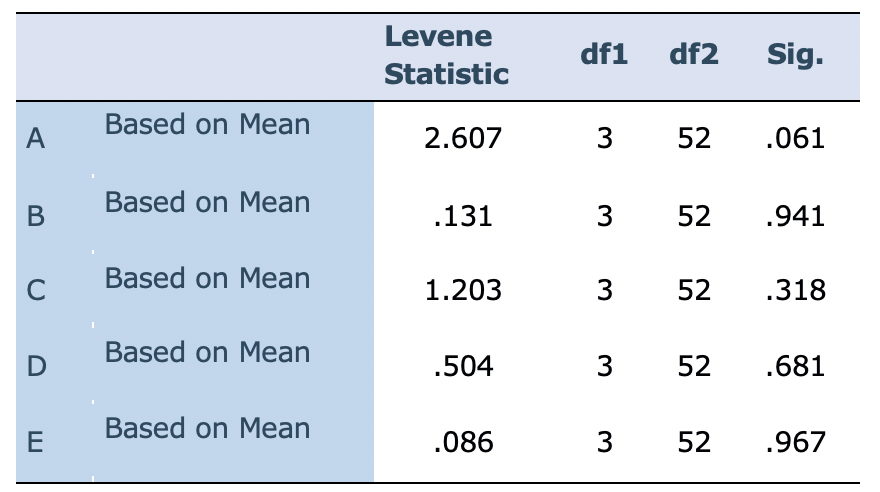
Table 9: Levene's Test of Equality of Error Variances
Table 9 shows that the interaction effect is statistically significant (the p-value for Wilks' Lambda is smaller than the alpha level of .05). There was a significant interaction between treatment type and time, Wilks’ Lambda = .09, F (4, 49) = 16, p <.001, partial eta squared = .55.
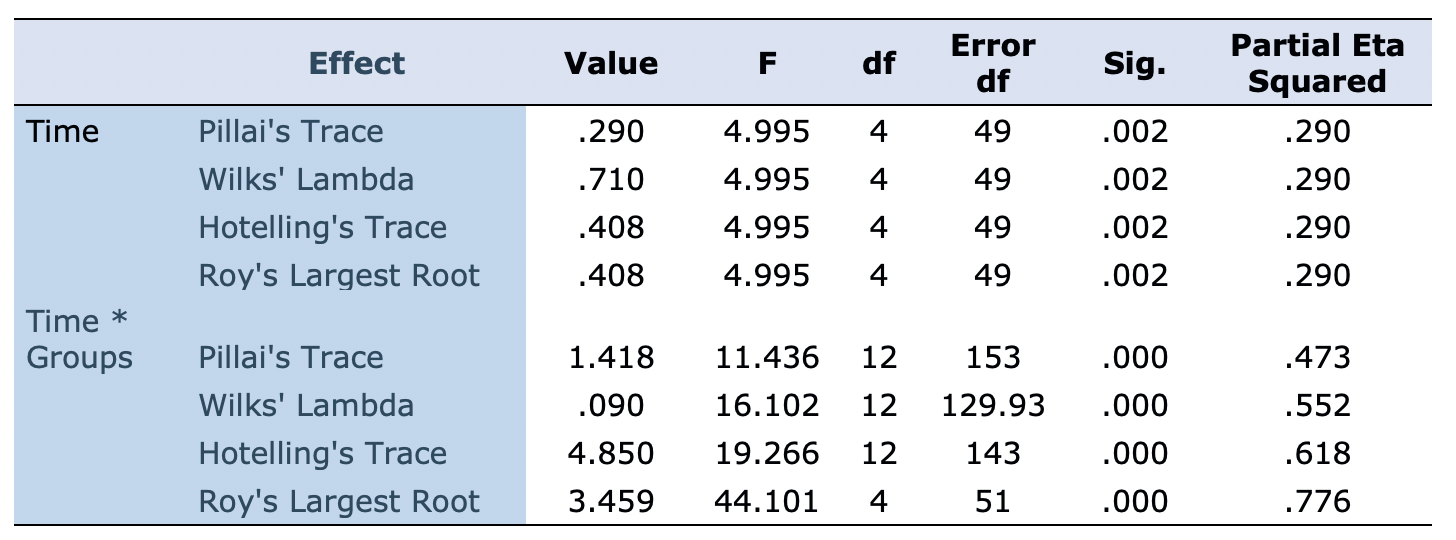
Table 10: Multivariate Tests
As Table 11 suggests, the main effect comparing the two types of the intervention was not significant, F (1, 52) = 135, p < .001, partial eta squared = .88, suggesting a difference in the effectiveness of the teaching approaches.

Table 11: Tests of Between-Subjects Effects for Exercises
Since a statistically significant difference exists between the performances of the groups, a means plot can clarify the position of the means of each group from the time one to time five (Figure 1).
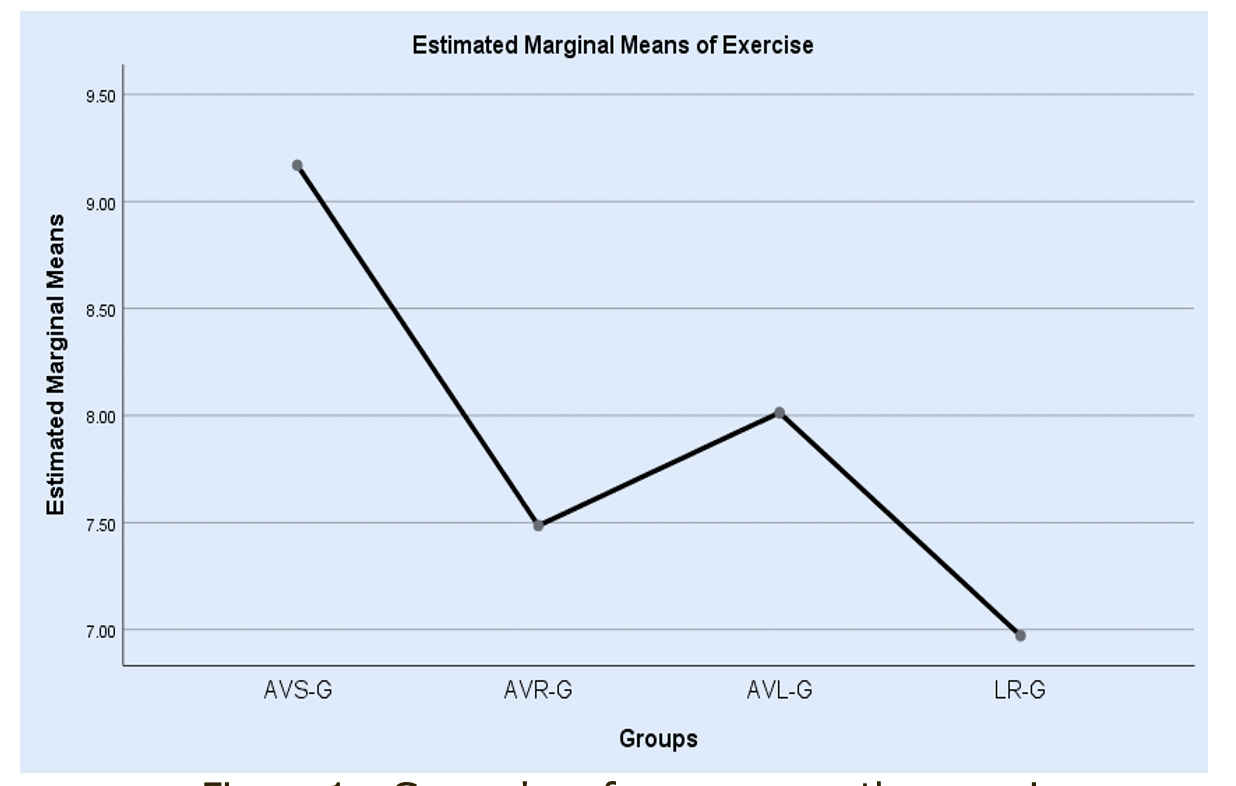
Figure 1 : Groups' performances on the exercices
Retrospective Questionnaire
Table 11 demonstrates the results of the retrospective questionnaire. The researchers calculated the frequency of the participants' answers to the questions. Forty-five participants had selected the first option of "helped me very much," and 11 had selected "helped me" for the first question. Regarding the second question, 30 participants had selected "helped me very much," 17 had selected "helped me," six had chosen "to some extent," and three "very little." Surprisingly, fill-in-the-blanks exercises (third question) had “helped” 45 students “very much”, nine had selected "helped me," and two students had decided on "to some extent" and "very little" options. The fourth question asked whether the technical words in the videos had a role in impeding the participants' comprehension. Fortunately, 32 participants had selected "never" and 16 "rarely." However, six learners believed that the technical terms hindered their comprehension "sometimes," and two believed "usually." The overall evaluations of 42 participants of the instruction were "very useful," and ten thought it to be "useful," whereas, four students had selected "to some extent."
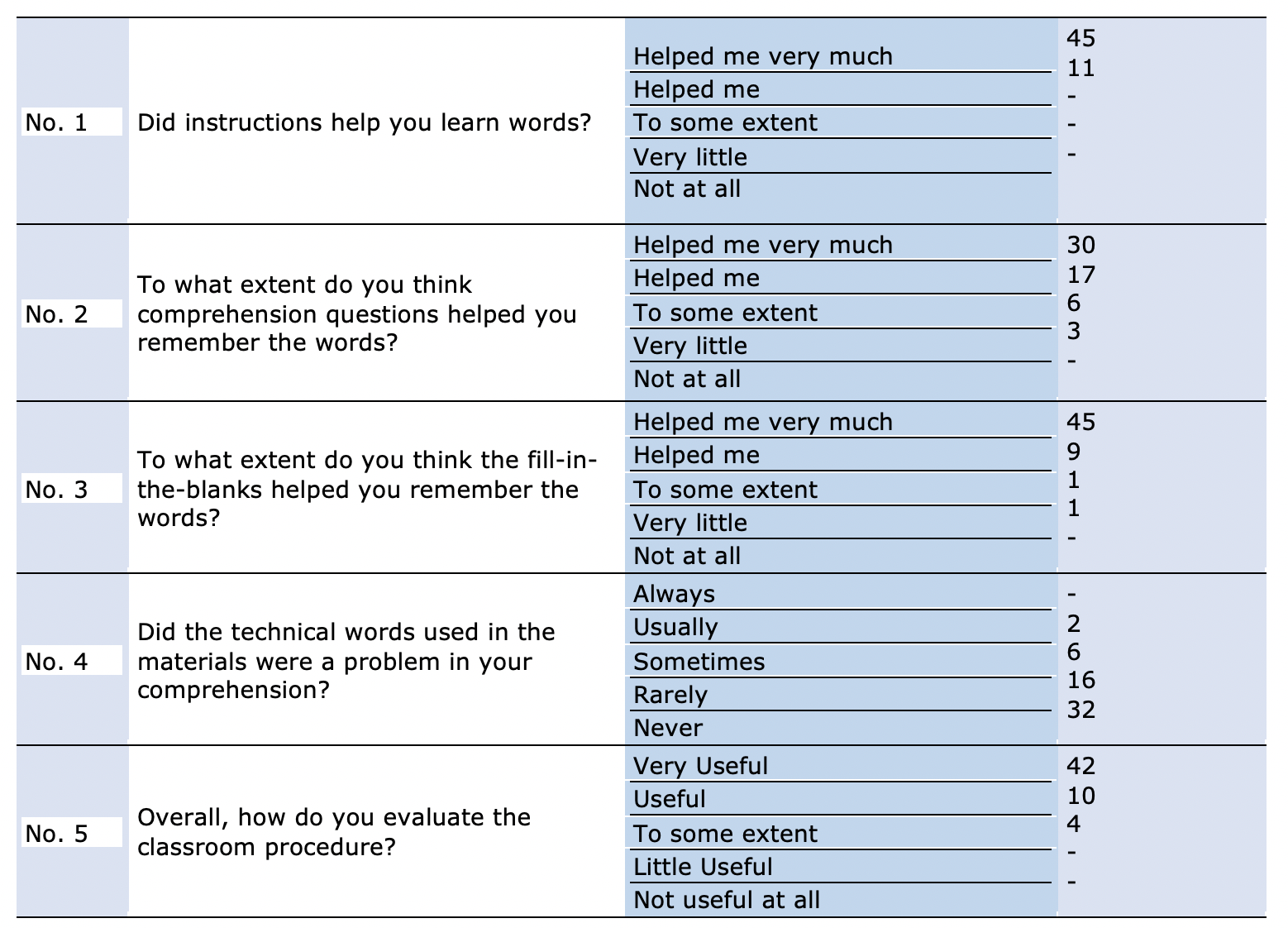
Table 12: Retrospective questionnaire results
As the final question, at the end of the questionnaire, the researchers asked the participants to rank the most useful activities or strategies (Table 13). The participants in the experimental groups selected videos as the first most beneficial activity. Fifty students chose fill-in-the-blanks as the other valuable activity. The third most successful practice was option "b" for the experimental groups, while the control group had selected "comprehension questions" (option c).
 Table 13: List of activities participants ranked
Table 13: List of activities participants ranked
Discussion
The findings can be discussed from several perspectives. The outperformance of AVS-G against the groups that practiced the receptive skills of listening and reading (AVL-G and AVR-G) leads researchers to answer the first research question positively. The results highlight the role of "meaning-focused spoken output" (Webb, 2020, p. 8) in learning and remembering vocabulary. This inference is substantiated by the fact that audiovisual input was manipulated in all experimental groups. Thus, the statistically significant difference found between the groups was due to the mode of practice. The classroom discussions during which the teacher tried to draw learners' attention toward the target words were responsible for vocabulary learning and retention.
Moreover, the researchers conclude that speaking provided a higher "frequency of occurrence" (Laufer & Rozovski-Roitblat, 2011) to the target words than listening and reading since interactions are composed of listening and speaking while in AVL-G and AVR-G, only listening and reading modalities were involved. During group discussions, the students used the words to express ideas and heard the words from classmates. In this process, the role of TED-ED videos is worthy of attention. They attracted the learners' attention to the content, stimulated interaction, and directed the course of discussion among learners. Thus, the researchers put forth that audiovisual input followed by spoken output fosters vocabulary learning more than when audiovisual input is followed by listening or reading. This result finds support from Swain's (1985) output hypothesis and Long's (1981) interaction hypothesis. Consistent with the results of the current study, some research findings also point to the role of speaking in vocabulary learning (Newton, 2013; Nguyen & Boers, 2018).
Another finding comes from the superiority of AVL-G to AVR-G and LR-G indicated by the statistical analysis. As revealed, listening was more useful than reading that followed the audiovisual input. This finding, following Vidal (2011), indicated that the participants who benefitted from listening had higher vocabulary achievement than those engaged in reading activities. One assumption for the insufficiency of reading as the most prominent input modality could be associated with the changes nowadays reading has undergone due to the advent of technology in human life. The popularity of reading from electronic pages such as social media, e-books, and the internet may explain why AVR-G participants were not as successful as AVS-G and AVL-G in learning vocabulary as indicated by the immediate and delayed post-tests. The efficacy of speaking and listening skills contradict the research findings, which have pointed to reading as the most appropriate source of input for vocabulary learning (e.g., Nagy et al., 1985; Paribakht & Wesche, 1999). The supremacy of listening to reading input attained in the present study was inconsistent with Ponniah (2011).
Additionally, the efficiency of audiovisual input in experimental groups in contrast to the control group (LR-G) is in line with studies that have shown the influential role of audiovisual input in vocabulary acquisition (Lin, 2014; Montero Perez et al., 2014, Sydorenko, 2010). The results of the responses to the questionnaire also verified the role of TED-ED videos as the most useful activity manipulated during the treatment. Several justifications can be provided for this finding. The first conclusion is that the films provided a richer context to guess the meaning of the words than listening and reading input offered in the control group. An alternative reason is that the experimental groups experienced a more profound cognitive involvement than the learners in the control group. Thus, the animations could facilitate vocabulary learning and retention. It could be stated that the animated visual pictures coordinated with narration could enhance learners' ability to process information. This assumption is similar to Paivio's (1986, 2007) Dual Coding Theory, which asserts that a combination of pictures and verbal input enhances information processing. Researchers propose that watching videos promotes learners' focus of attention on the content of the input and facilitates guessing from the context, as the most powerful strategy for vocabulary learning (Nation, 2013).
A further assumption is that audiovisual input can provide learners with meaningful data that cluster and join the existing knowledge. This process facilitates interpretation and leads to meaningful learning as the data are stored in schemata in the long-term memory. This process helps learners in remembering the context and the words they encountered while watching the films. Denoting that AVS-G outperformed the other groups on the delayed post-test indicates that the data transfer to long-term memory had occurred successfully (Randall, 2007). In other words, speaking facilitated understanding of the message and helped learners focus on the target words. The use of words for conveying ideas during speaking enabled the participants to pass the concepts to the long-term memory for storage.
Baddeley's (1986) three-component model of working memory can provide an alternate interpretation. Baddeley believes in the separation of the memory into two visual and phonological stores and argues that auditory data are processed separately, which leads to less overload of the working memory's limited capacity. Following this model, the modality effect (Castro-Alonso & Sweller, 2020) assumes that multimedia supplemented by spoken language is more useful than when multimedia is accompanied by written form. Thus, the researchers of the present study argue that audiovisual input can activate a substantial working memory capacity to perform on data received. Since it has less load on the participants' cognitive capacity, vocabulary retention occurs with much ease. This assumption draws on Ellis' (2001) model of working memory for language acquisition. Visual input and auditory input received via videos merge to establish a connection between words and the context, which itself is the manifestation of several relationships. That is, audiovisual input provides an extensive stimulus for the working memory available for learners (Randal, 2007). It enables learners to activate their schemata for retention of the word meanings, as demonstrated in the delayed post-test.
One factor that facilitates comprehension is to focus on the message rather than language constituents. The findings suggest that watching the animations and listening to the message simultaneously direct learners' attention to the content as a whole and encourages them to guess the meanings of the words and follow the flow of information. It can be contended that learners' quest for understanding the message leads to successful guessing. This process, as Van Patten and Benati (2010) put forth, leads to incidental learning of the new words.
The results obtained from the performance of the participants on the written tasks are worthy of attention. AVS-G gained the highest mean score for the number of times that the group members used the target words accurately in answering the comprehension questions. This finding verified the results obtained from the learners' performance in immediate and delayed post-tests. The predominance of AVS-G was also confirmed by the between-within subjects ANOVA on the fill-in-the-blanks exercises. These findings can be viewed from two perspectives. First, regarding productive skills, speaking seems to be more important than writing in vocabulary learning. Second, the type of writing activities (tasks for incidental learning and exercises for intentional learning) does not have a differential role in vocabulary acquisition. However, they are outstanding in providing more practice. The steady superiority of AVS-G to other groups, in all tests, attests to this assertion. If writing activities had caused significant differences in vocabulary learning, the groups should have shown fluctuations in their performances. This finding indicates divergence from Laufer (2006) and Laufer and Rozovski-Roitblat (2011) regarding the roles of Focus on Form and Focus on Forms activities in vocabulary acquisition. However, the participants' preferences for the second worksheet verifies the function of exercises associated with intentional vocabulary learning.
Drawing on Nation's (2007) four-strand approach, the researchers argue that using different types of activities pertaining to incidental and intentional vocabulary learning is legitimate and can lead to the success of learners. This conclusion finds support from the participants' perceptions regarding the usefulness of fill-in-the-blanks exercises in vocabulary learning. The use of language skills (listening, reading, and speaking) as classroom practices is in favor of incidental vocabulary learning (Nation, 2020); however, the role of exercises that represent intentional learning cannot be ignored.
Additionally, the function of audiovisual input, selected by all experimental groups as the most beneficial activity in their response to the retrospective questionnaire, cannot be overlooked as they provided an appropriate context for learning vocabulary. Although many technical words were used in the films, the animations facilitated guessing word meanings, as stated by the majority of the participants. The researchers conclude that incorporating different input modalities leads to more beneficial results in vocabulary acquisition, a conclusion that finds support from the modality principle proposed by Atkinson (2005), who argues for the superiority of multimedia learning. As Atkinson argues, the teaching materials in which pictures accompany words have the viability to be better remembered. However, TED-ED videos' efficiency should be considered in the shadow of the participants' language proficiency level.
Conclusion
The present study integrated audiovisual input with different input or output activities to explore which language modality could be more beneficial in vocabulary learning. The purpose of the study was to portray how the amalgamation of various activities could lead to learners' success in learning and remembering English words. This study was innovative in employing TED-ED videos, and the success of the participants, partly, was because the films combined interesting subjects with animations, which facilitated guessing the meaning of the words and helped learners use them in different classroom practices. Overall, the results showed that incidental vocabulary learning in which learners try to communicate via meaning-based spoken output is superior to other ways of vocabulary acquisition. However, employing form-based activities could not be entirely ignored.
The findings can be useful for EFL teachers and can give them ideas about employing innovative methods in the classroom environment. In EFL settings, finding appropriate input to expose language learners could be challenging; thus, using TED-ED videos could be beneficial. However, replication of the study in other contexts and with different learners is necessary to confirm the usefulness of TED-ED videos for vocabulary learning. Material developers can consider the videos as sources for vocabulary teaching. The results can draw the attention of SLA researchers to focus on meaning-focused spoken activities in vocabulary acquisition by using audiovisual input.
The study was limited in the number of participants in the study groups, and thus, further research can verify the results. The study also could not provide exact measures of the number of times each group encountered the target words. However, as the results have shown, think-aloud protocols and interviews could help researchers learn about the strategies learners use while trying to learn words. The study did not consider the parts of speech in selecting and teaching the words. In sum, the current research showed the benefits of using audiovisual input in EFL classes. Its primary importance was in using speaking as the mode of practice. The researchers hope the study will encourage EFL teachers to use TED-ED videos as a source of input for language learning.
References
Aguirre, C. (2015, November). What would happen if you didn’t sleep? [Video]. TED-ED. https://www.ted.com/watch/ted-ed
Atkinson, R. K. (2005). Multimedia learning in mathematics. In R. E. Mayer (Ed.), The Cambridge handbook of multimedia learning (pp. 393-408). Cambridge University Press.
Baddeley, A. D. (1986). Working memory. Clarendon Press.
Baddeley, A. D. (1992). Working memory. Science, 255(5044), 556-559. https://doi.org/10.1126/science.1736359
Baddeley, A. D. (1997). Human memory: Theory and practice. Psychology Press.
Brown, J. D. (2005). Testing in language programs: A comprehensive guide to language assessment. McGraw Hill.
Bryce, E. (2015, April). What really happens to the plastic you throw away? [Video]. TED-ED. https://www.ted.com/watch/ted-ed
Buffington, T. (2016, April). Why do cats act so weird? [Video]. TED-ED. https://www.ted.com/watch/ted-ed
Castro-Alonso, J. C., & Sweller, J. (2020). The modality effect of cognitive load theory. In W. Karwowski, T. Ahram, & S. Nazir (Eds.). Advances in human factors in training, education, and learning sciences, AHFE 2019. Advances in Intelligent Systems and Computing, 963. (pp. 75-84)., https://doi.org/10.1007/978-3-030-20135-7_7
Chen, C., & Truscott, J. (2010). The effects of repetition and L1 lexicalization on incidental vocabulary acquisition. Applied Linguistics, 31(5), 693-713. http://dx.doi.org/10.1093/applin/amq031
Clark, M. (2013). The use of technology to support vocabulary development of English language learners. Education Masters. Paper 238. https://fisherpub.sjfc.edu/education_ETD_masters/238
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Lawrence Erlbaum.
Collins, A. (2014, July). How playing an instrument benefits your brain. [Video]. TED-ED. https://www.ted.com/watch/ted-ed
Creswell, J. W. (2015). A concise introduction to mixed methods research. Sage.
Dang, T. N. Y., Coxhead, A., & Webb, S. (2017). The academic spoken word list. Language Learning, 67(4), 959–997. https://doi.org/10.1111/lang.12253
Ellis, N. C. (2001). Memory for language. In P. Robinson (Ed.), Cognition and second language instruction (pp. 33–68). Cambridge University Press.
Elgort, I., Brysbaert, M., Stevens, M., & Van Assche, E. (2018). Contextual word learning during reading in a second language: An eye-movement study. Studies in Second Language Acquisition, 40(2), 341–366. https://doi.org/10.1017/S0272263117000109
Farrell, H. (2017, February). What is bipolar disorder? [Video]. TED-ED. https://www.ted.com/watch/ted-ed
Gass, S. (1999). Discussion: Incidental vocabulary learning. Studies in Second Language Acquisition, 21(2), 319-333. http://dx.doi.org/10.1017/S0272263199002090
Godfroid, A. (2019). Sensitive measures of vocabulary knowledge and processing: Expanding Nation's framework. In S. Webb (Ed.). The Routledge handbook of vocabulary studies (pp.433-453). Routledge.
Hsueh-Chao, M. H., & Nation, P. (2000). Unknown vocabulary density and reading comprehension. Reading in a Foreign Language, 13(1), 403–430. https://doi.org/10125/66973
Hulstijn, J. (2001). Intentional and incidental second-language vocabulary learning: A reappraisal of elaboration, rehearsal and automaticity. In P. Robinson (Ed.), Cognition and second language instructions (pp. 258–286). Cambridge University Press. http://dx.doi.org/10.1017/CBO9781139524780.011
Krashen, S. (1989). We acquire vocabulary and spelling by reading: Additional evidence for the Input Hypothesis. The Modern Language Journal, 73(4), 440-464. https://doi.org/10.1111/j.1540-4781.1989.tb05325.x
Kress, G. R. (2010). Multimodality: A social semiotic approach to contemporary communication. Routledge.
Lin, P. M. S (2014). Investigating the validity of internet television as a resource for acquiring L2 formulaic sequences. System, 42, 164-176. https://doi.org/10.1016/j.system.2013.11.010
Laufer, B. (2005). Focus on form in second language vocabulary learning. EUROSLA Yearbook 5., 223-250. http://dx.doi.org/10.1075/eurosla.5.11lau
Laufer, B. (2006). Comparing focus on form and focus on FormS in second language vocabulary learning. Canadian Modern Language Review, 63(1), 149–166. https://doi.org/10.3138/cmlr.63.1.149
Laufer, B., & Rozovski-Roitblat, B. (2011). Incidental vocabulary acquisition: The effects of task type, word occurrence and their combination. Language Teaching Research, 15(4), 391-411. https://doi.org/10.1177/1362168811412019
Long, M. H. (1981). Input, interaction, and second-language acquisition. Annals of the New York Academy of Sciences, 379(1), 259–278. https://doi.org/10.1111/j.1749-6632.1981.tb42014.x
Mizumoto, A., & Takeuchi, O. (2009). Examining the effectiveness of explicit instruction of vocabulary learning strategies with Japanese EFL university students. Language Teaching Research, 13(4), 425-449. https://doi.org/10.1177/1362168809341511
Montero Perez, M., Peters, E., Clarebout, G., & Desmet, P. (2014). Effects of captioning on video comprehension and incidental vocabulary learning. Language Learning & Technology, 18(1), 118-141. http://dx.doi.org/10125/44357
Nagy, W. E., Herman, P. A., & Anderson, R. C. (1985). Learning words from context. Reading Research Quarterly, 20(2), 233-253. https://doi.org/10.2307/747758
Nation, I. S. P. (2001). Learning vocabulary in another language. Cambridge University Press.
Nation, P. (2007). The four strands. Innovation in Language Learning and Teaching, 1(1), 1–12. https://doi.org/10.2167/illt039.0
Nation, P. (2013). Vocabulary learning and teaching. In P. Robinson (Ed.). The Routledge encyclopedia of second language acquisition (pp. 682- 686). Taylor & Francis.
Nation, P. (2020). The different aspects of vocabulary knowledge. In S. Webb (Ed.). The Routledge handbook of vocabulary studies (pp. 15-29). Routledge.
Newton, J. (2013). Incidental vocabulary learning in classroom communication tasks. Language Teaching Research, 17(2), 164-187. https://doi.org/10.1177/1362168812460814
Nguyen, C. D., & Boers, F. (2018). The effect of content retelling on vocabulary uptake from a TED Talk. TESOL Quarterly, 53 (1), 5-29. https://doi.org/10.1002/tesq.441
Paivio, A. (1986). Mental representations: A dual coding approach. Oxford University Press.
Paivio, A. (2007). Mind and its evolution: A dual coding theoretical approach. Lawrence Erlbaum.
Paribakht, T. S., & Wesche, M. (1999). Reading and "incidental" L2 vocabulary acquisition: An introspective study of lexical inferencing. Studies in Second Language Acquisition, 21(2), 195-224. http://dx.doi.org/10.1017/S027226319900203X
Pellicer-Sánchez, A. (2016). Incidental L2 vocabulary acquisition from and while reading: An eye tracking study. Studies in Second Language Acquisition, 38(1), 97–130. https://doi.org/10.1017/S0272263115000224
Pellicer-Sánchez, A. (2020). Learning single word vs. multiword items. In S. Webb (Ed.). The Routledge handbook of vocabulary studies(pp. 158-173). Routledge.
Pellicer-Sánchez, A., & Schmitt, N. (2010). Incidental vocabulary acquisition from an authentic novel: Do Things Fall Apart? Reading in a Foreign Language, 22(1), 31–55. http://www.nflrc.hawaii.edu/rfl/April2010/articles/pellicersanchez.pdf
Peters, E., Heynen, E., & Puimège, E. (2016). Leaning vocabulary through audiovisual input: The differential effect of L1 subtitles and captions. System, 63(4), 134-148. https://doi.org/10.1016/j.system.2016.10.002
Pinker, S. (1991). Rules of language. Science, 253(5019), 530–535. https://doi.org/10.1126/science.1857983
Plass, J. L., & Jones, L. C. (2005). Multimedia learning in second language acquisition. In R. Mayer (Ed.), The Cambridge handbook of multimedia learning (pp. 467–488). Cambridge University Press.
Ponniah, R. J. (2011). Incidental acquisition of vocabulary by reading. The Reading Matrix, 11(2), 135-139. http://www.readingmatrix.com/articles/april_2011/ponniah.pdf
Rashtchi, M., & Aghili, H. (2014). Computerized input enhancement versus computer-assisted glosses: Do they affect vocabulary recall and retention? Theory and Practice in Language Studies, 4(8), 1665-1674. https://doi.org/10.4304/tpls.4.8.1665-1674
Rashtchi, M., & Tollabi Mazraehno, M. R. (2019). Exploring Iranian EFL learners' listening skills via TED talks: Does medium make a difference? Journal of Language and Education, 5(4), 81-97. https://doi.org/10.17323/jle.2019.9691
Randall, M. (2007). Memory, psychology and second language learning. John Benjamins.
Rodgers, M. P. H. (2013). English language learning through viewing television: An investigation of comprehension, incidental vocabulary acquisition, lexical coverage, attitudes and captions (Unpublished doctoral dissertation). Wellington, Victoria University.
Saslow, J., & Ascher, A. (2006a). Top notch (2 and 3). Pearson Longman.
Saslow, J., & Ascher, A. (2006b). Summit (1 and 2). Pearson Longman.
Schmitt, N. (2008). Instructed second language vocabulary learning. Language Teaching Research, 12, 329–363. https://doi.org/10.1177/1362168808089921
Swain, M. (1985). Communicative competence: Some roles of comprehensible input and comprehensible output in its development. In S. Gass & C. Madden (Eds.), Input in second language acquisition (pp. 235–253). Newbury House.
Sydorenko, T. (2010). modality of input and vocabulary acquisition. Language learning and Technology, 14(2), 50-73. http://llt.msu.edu/vol14num2/sydorenko.pdf
VanPatten, B., Benati, A. G. (2010). Key terms in second language acquisition. Continuum.
van Zeeland, H., & Schmitt, N. (2013). Lexical coverage in L1 and L2 listening comprehension: The same or different from reading comprehension? Applied Linguistics, 34(4), 457–479. https://doi.org/10.1093/applin/ams074
Vidal, K. (2011). A comparison of the effects of reading and listening on incidental vocabulary acquisition. Language Learning, 61(1), 219–258. https://doi.org/10.1111/j.1467-9922.2010.00593.x
Webb, S. (2007a). The effects of repetition on vocabulary knowledge. Applied Linguistics, 28, 46–65. https://doi.org/10.1093/applin/aml048
Webb, S. (2007b). Learning word pairs and glossed sentences: The effects of a single sentence on vocabulary knowledge. Language Teaching Research, 11(1), 63–81. https://doi.org/10.1177/1362168806072463
Webb, S. (2008). The effects of context on incidental vocabulary learning. Reading in a Foreign Language, 20(2),232-245.http://nflrc.hawaii.edu/rfl
Webb, S. (2020). Introduction. In S. Webb (Ed.). The Routledge handbook of vocabulary studies (pp. 1-12). Routledge.
Wesche, M., & Paribakht, T. S. (1996). Assessing second language vocabulary knowledge: Depth versus breadth. Canadian Modern Language Review, 53(1), 13–40. https://doi.org/10.3138/cmlr.53.1.13
Winke, P., Gass, S., & Sydorenko, T. (2013). Factors influencing the use of captions by foreign language learners: An eye-tracking study. The Modern Language Journal, 97(1), 254-275. http://dx.doi.org/10.1111/j.1540-4781.2013.01432.x
Yanagisawa, A., & Webb, S. (2020). Measuring depth of vocabulary knowledge. In S. Webb (Ed.). The Routledge handbook of vocabulary studies (pp. 371- 386). Routledge.
Zimmerman, C. B. (2014). Teaching and learning vocabulary for second language learners. In M. Celce-Murcia, D. M. Brinton, & M. A. Snow (Eds.), Teaching English as a second or foreign language (288-302). National Geographic Learning
